アペルザで主に検索エンジンなどのバックエンドを担当している上保と申します。今日は検索エンジンまでのデータフローに関してお話したいと思います。
概要
アペルザは製造業のための製品検索やカタログ検索などのサービスを提供しています。複数のデータソースから取得されたデータは一旦マスタデータベースに蓄積され、ETLを経由して検索エンジンに取り込まれています。
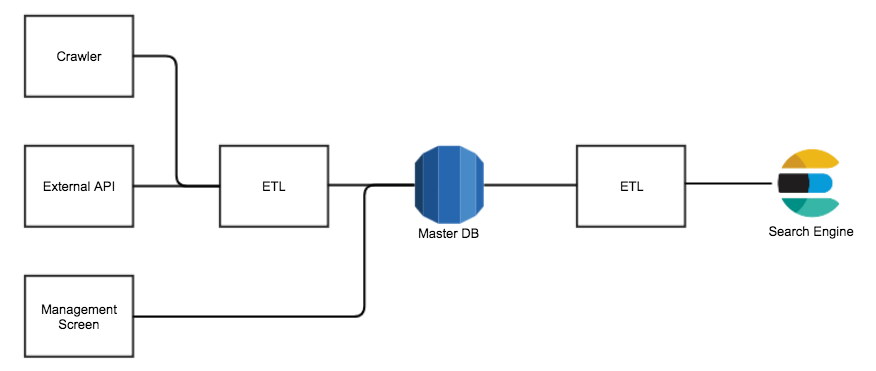 2種類のETLがマスタデータベースと検索エンジンの前にそれぞれ存在しており、前者をDB ETL、後者をSearch ETLと呼んでいます。それぞれのETLの前にはQueueを介在させ、非同期かつ並列して処理が行えるようになっています。
2種類のETLがマスタデータベースと検索エンジンの前にそれぞれ存在しており、前者をDB ETL、後者をSearch ETLと呼んでいます。それぞれのETLの前にはQueueを介在させ、非同期かつ並列して処理が行えるようになっています。
イベント処理
 QueueにはPublisherが発行したイベントデータがJSONで蓄積されています。Consumerはそこからデータ種別やデータの更新範囲を特定する情報を読み取り、適切なETLを実行します。この時既に実行中のETLの数が定められた並列数の閾値を越えている場合はその回の処理を見送ってスリープします。データをなるべく早く反映させたいものの、データベースや検索エンジンなどの負荷を過度に上げないように調整しています。閾値はデータの優先順位によっても値が変わり、高いデータはギリギリまで頑張りますが、それ以外は安定性を重視です。速度と安定性のバランスを取ることや、運用の手間を極力減らすことがこのシステムのポイントになっています。
QueueにはPublisherが発行したイベントデータがJSONで蓄積されています。Consumerはそこからデータ種別やデータの更新範囲を特定する情報を読み取り、適切なETLを実行します。この時既に実行中のETLの数が定められた並列数の閾値を越えている場合はその回の処理を見送ってスリープします。データをなるべく早く反映させたいものの、データベースや検索エンジンなどの負荷を過度に上げないように調整しています。閾値はデータの優先順位によっても値が変わり、高いデータはギリギリまで頑張りますが、それ以外は安定性を重視です。速度と安定性のバランスを取ることや、運用の手間を極力減らすことがこのシステムのポイントになっています。
次回はこれらの仕組みを具体的に何を使って実現しているのかをお話します。