Self Introduction
こんにちは! 山崎といいます。主にアペルザのプラットフォーム関連を担当しています。
今回は、アペルザのクローラプラットフォームについて紹介したいと思います。
Overview for the Aperza Crawler Platform
私達のクローラプラットフォームは製造業の商品を汎用的にクロール出来るものを目指して開発しました。そして現在はオペレータでも簡単にクロール出来るようツールや管理画面を提供しています。
それでは、実際にどのようなものなのか紹介したいと思います。
System Architecture

Operation Flow
Get target Xpath by Chrome extention
クロール対象Webサイトから商品データを取得するためのXpathを取得します。Set target Xpath to each site’s config data on the Aperza Data Manager
クロール対象Webサイト毎のXpathなどクロールに必要なさまざまなデータを保存します。Crawl target site by config data.
設定されたデータを利用して対象Webサイトをクロールします。Store crawled product data to RDB.
クロールした対象Webサイトの商品データをRDBに保存します。Push product data to the Search Engine.
対象Webサイトの商品データクロール完了時にアペルザ検索エンジンにindexの登録依頼をします。
これでindex登録完了後にアペルザのサイトでクロールした商品が見れるようになります。
(アペルザ検索エンジンの解説については別途担当者がブログに書く予定です。)
Each Feature
それでは、各機能を開発秘話やテクニカルな面に触れつつ紹介します。
Aperza Crawler Configurator
Chrome extensionを利用しHTMLやXpathを理解するレベルのオペレータでもクロールに必要な情報をいかに簡単に対象Webサイトから取得するかを目指して開発しました。
特に対象の商品データをまとめて取得するためのXpathまわりの機能に拘りました。
開発着手時はChrome extensionの開発知識・経験が無かったため、公式ドキュメントと参考になりそうなChrome extensionのソースを解析しすすめていきました。
GUIベースでXpathを取得するオートモード
Chrome DeveloperツールのようなDOMのマウスオーバーハイライト機能などの実現
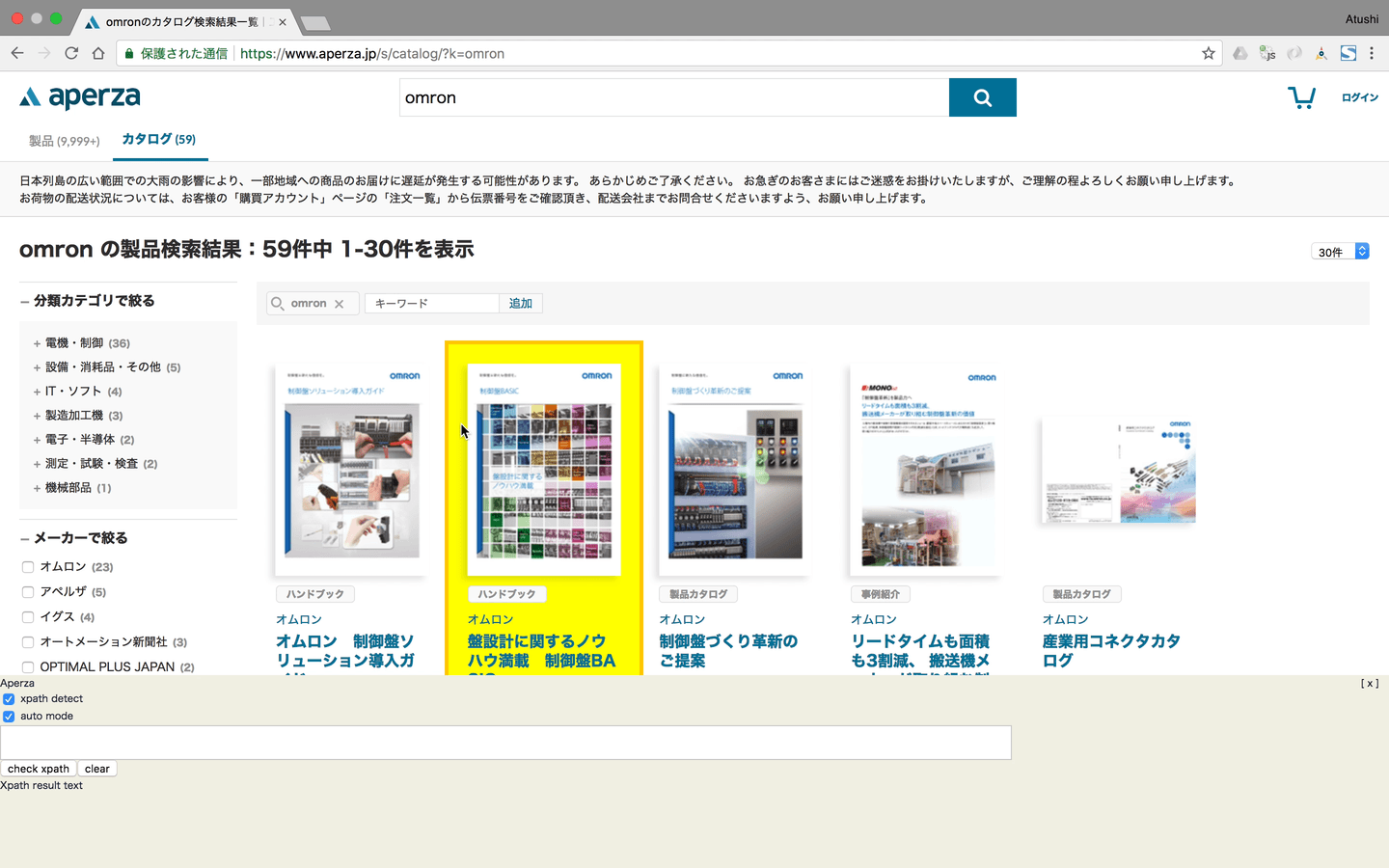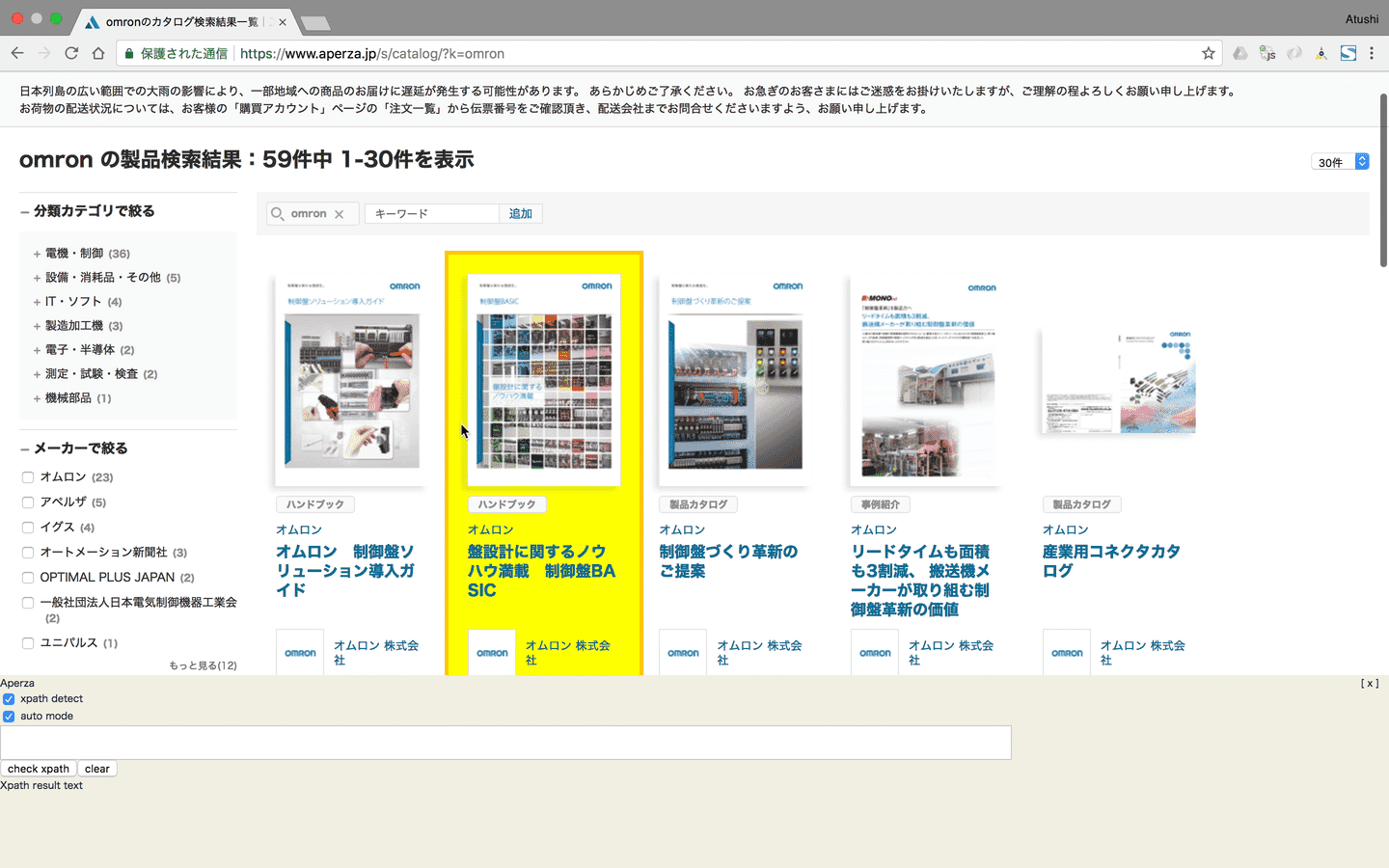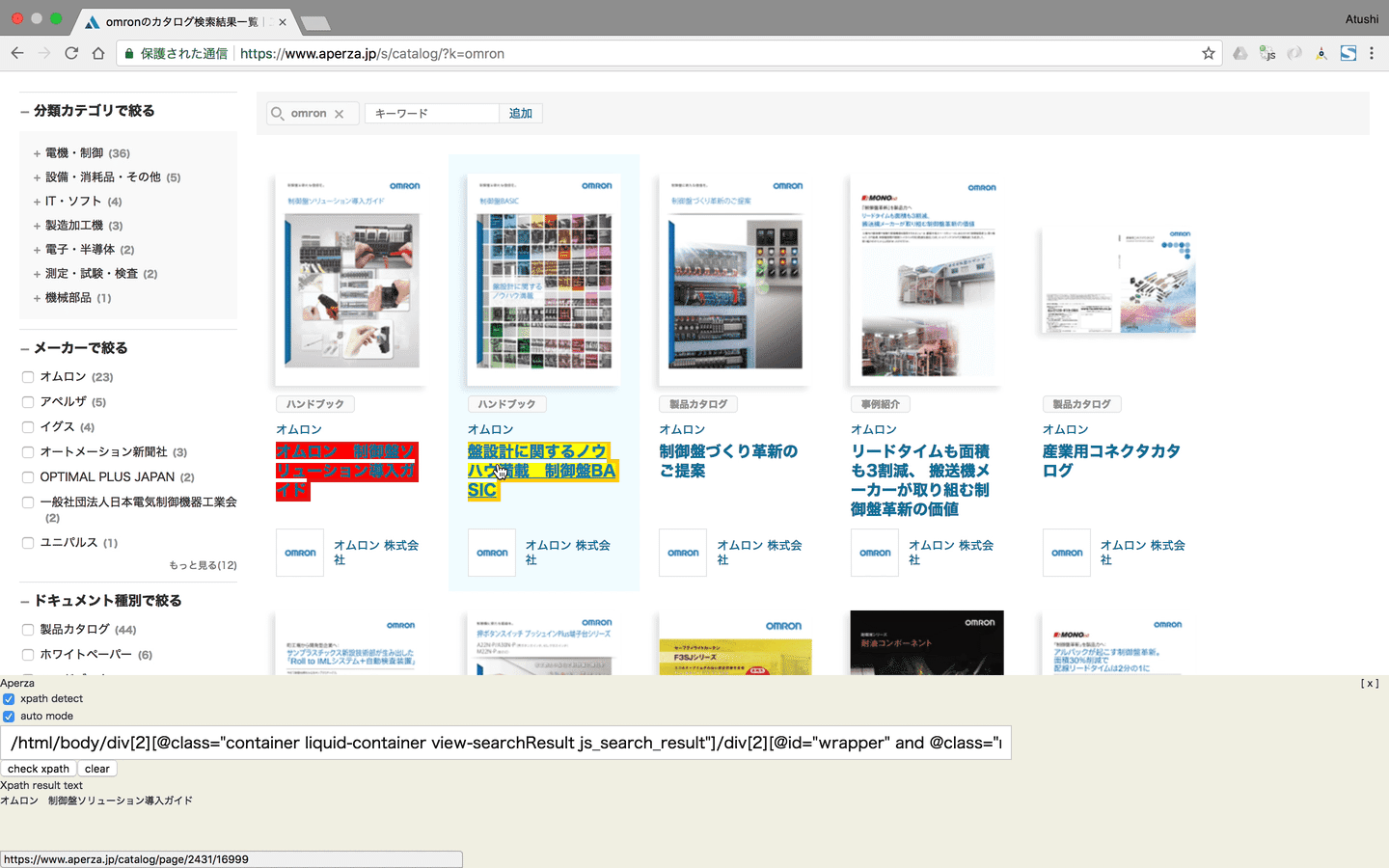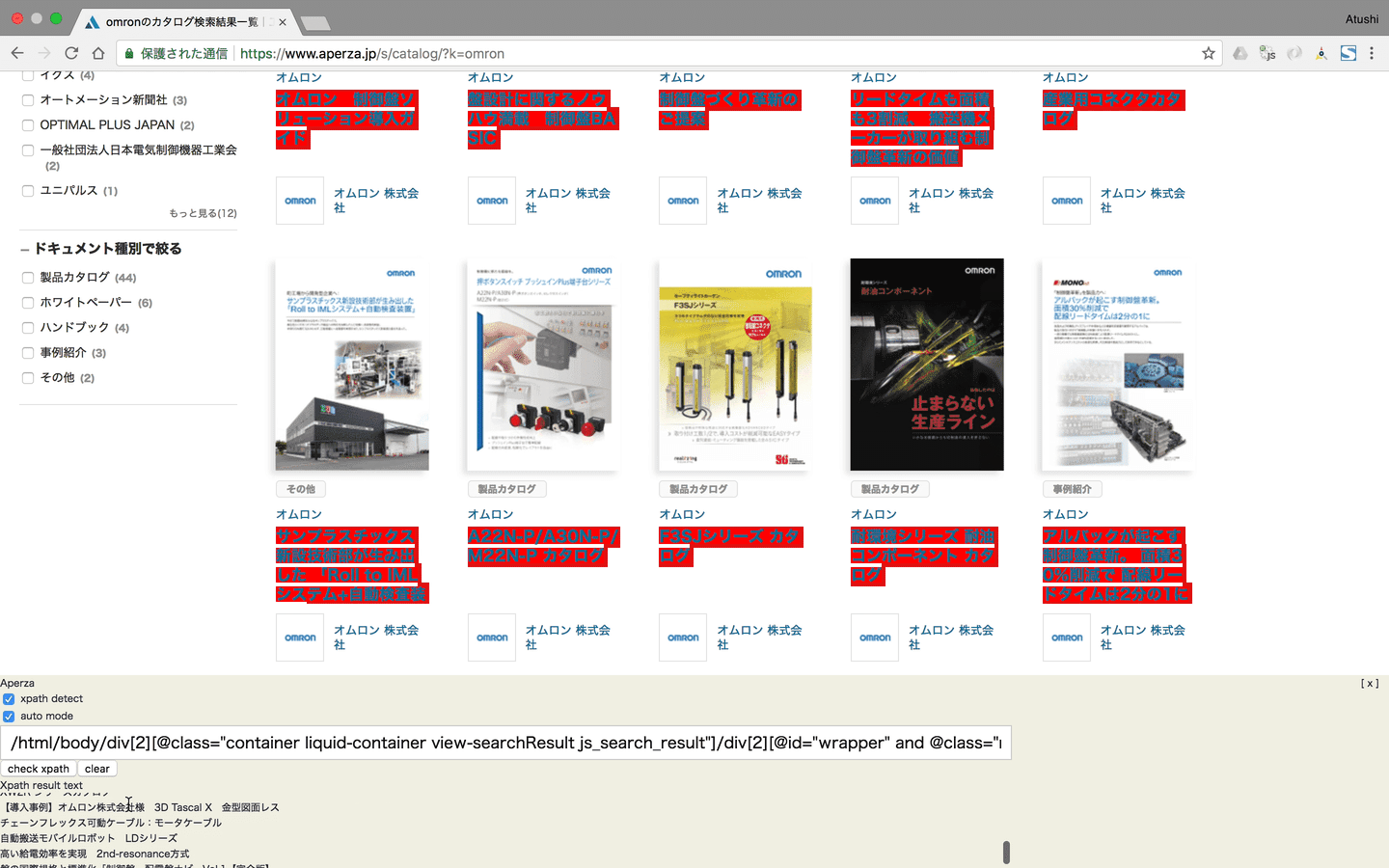
複雑なXpathを実行し実際のWebサイトで取得可能か確認するマニュアルモード
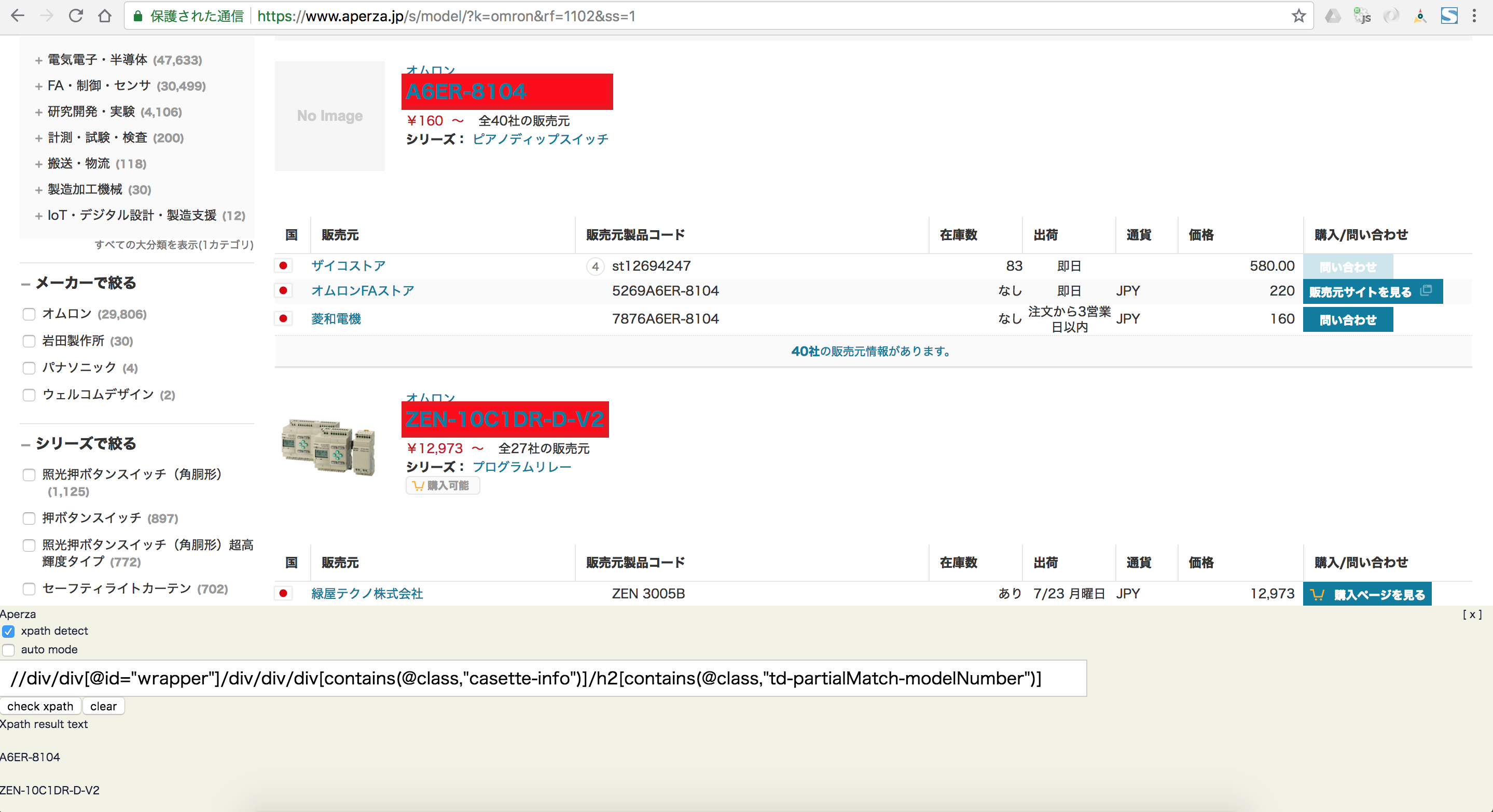
利用開始して分ったこと
中にはおもてなししすぎてもあまり利用されずに廃止になってしまった機能もあります。
それは文字コードや様々なクロール設定データをChrome extention経由でDBに直接登録する機能です。
なぜならAperza Data Managerが開発されクロール設定データを管理画面で便利に扱うことが出来るようになったからです。
またAperza Crawler ConfiguratorにはそもそもXpathの動作確認機能以外は必要ないということに気づけたからです。
Aperza Data Manager
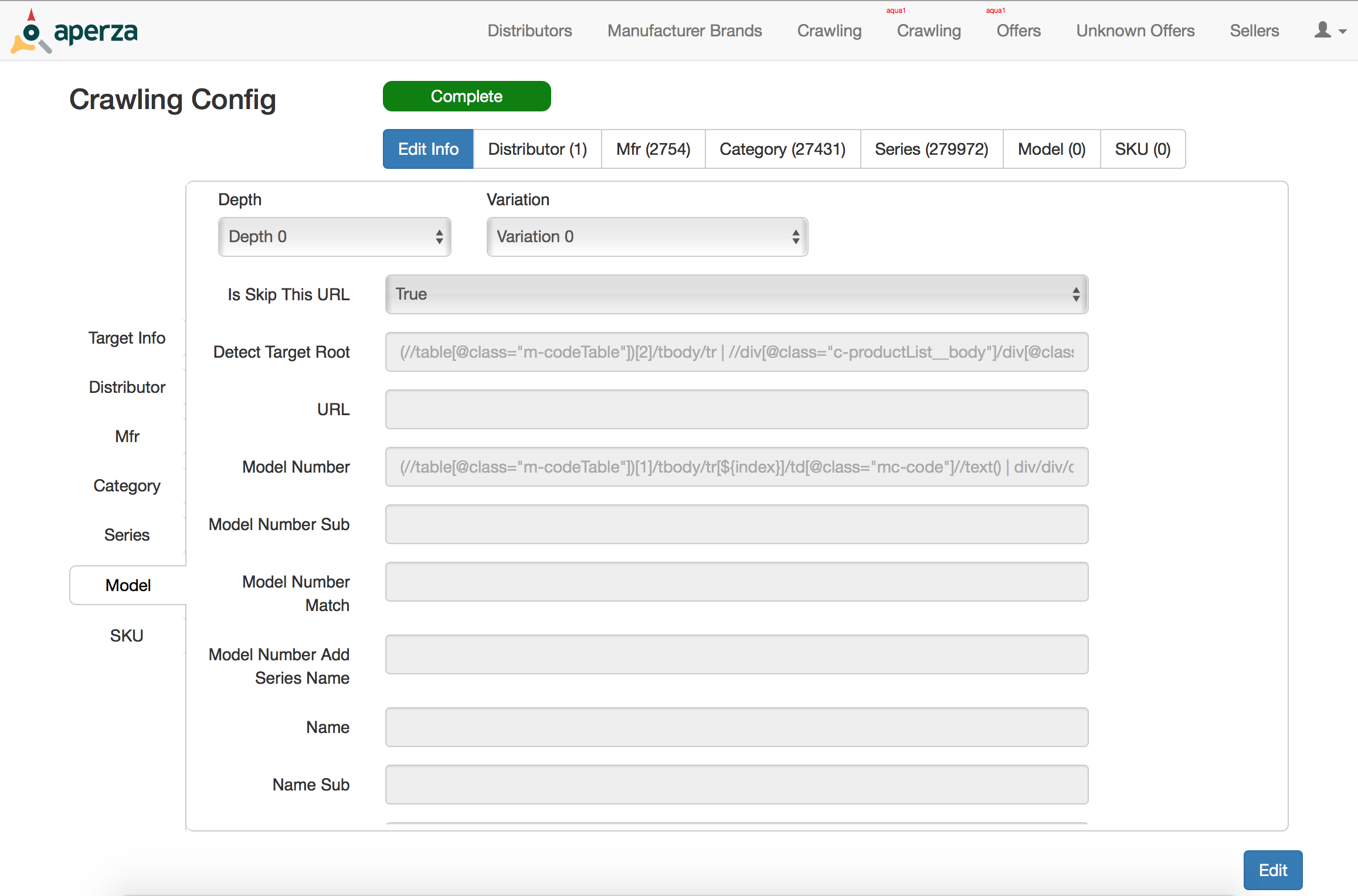 Node.jsのWebpackで開発された社内向けデータ管理用Webアプリケーションです。
Node.jsのWebpackで開発された社内向けデータ管理用Webアプリケーションです。
この社内サービスが出来たことにより飛躍的にクロール運用が効率的になりました。
Aperza Data Managerは以下の機能などを網羅しています。
- クロール対象のサイトの管理
- JIRAとのヒモ付による詳細作業ログの管理連携
- クロール設定情報の登録
- クローラの実行・実行ステータス参照
- クロール結果のデータ参照
- クロール結果をアペルザサービスへ反映
Aperza Crawler
Aperza CrawlerはRubyで開発されたクローラバッチサービスです。主に以下のライブラリを利用し自由度・カスタマイズ性を考慮しクロールライブラリの利用はしませんでした。
AWS Batchを利用しDockerコンテナ化されたバッチを好きなだけ様々なサイトを同時にクロールすることが出来ます。
Aperza Data Managerで設定された対象サイトのクロール情報を元にAperza Crawlerが以下のような挙動を行います。
- Robotexを利用し対象サイトのrobots.txtの情報を元に対象URLがクロールして問題ないかをチェックします。問題なければクロールを実施します。
- 対象URLに対しopen-uriで社内ツールJS Render(後述)経由アクセスします。理由はopen-uriだけだとHTMLがそのまま返却されるだけでJavascriptは動作していません。そのためJavascriptを動作させた上でHTMLを返却するJS Renderを利用しています。
- 取得した対象URLのHTMLをNokogiriを利用しAperza Data Managerで予め設定されたXpathで対象のDOMを特定し値を取得します。
- 取得した値をDBに保存します。
基本的には上記のことを行っているだけです。しかし、様々なクロール設定情報を予め登録しておくだけで
- 対象サイトの任意URLから商品のカテゴリ一覧をXpathで抜き出し、一覧のDOM内のカテゴリ情報をそれぞれDBに登録。
- 取得したカテゴリの詳細ページURLに遷移し各商品情報を予め設定されたXpathなどで取得しDBに登録。
などなどプログラムのループ処理やGet/Setのようなことが行なえます。また正規表現を利用してXpathで取得した値の加工や取得判定なども行っています。
気をつけたこと
クロール行為は時にサイトへの攻撃とみなされる場合があり、無自覚なまま犯罪行為を行ってしまうリスクがあります。
そのため我々のクローラプラットフォームでは様々な箇所に過度なアクセスを発生させないような仕組みを用意しました。
静的サイトクローラから動的サイトクローラへ
クローラ開発当初はwgetで取得したHTMLを予め保存しておき、何度でも対象Webサイトに負荷を与えずにクロールすること。また対象Webサイトの歴代HTMLをアペルザで保持し過去に遡ってクロール可能にすることを目的に静的サイトクローラを開発しました。
しかし、様々なWebサイトをクロールしていくとJavascriptが動作しないと取得出来ないデータが多く存在することが分かってきました。また過去に遡ってクロールすることのメリットが当時のアペルザにあまり無かったこと、クロールの運用や取得したい項目が明確になり何度でも同じHTMLをクロールする必要がなくなったこと。そのような経緯でJavascriptを動作させた上でのHTMLをリアルタイムアクセスで行う現在利用されている動的サイトクローラを開発しました。
JS Render
指定されたURLのHTMLをJavascriptを動作させた上で返却する社内APIです。
AWS API Gateway、AWS Lambda Function上でNode.jsから(すでに開発が終わってしまいましたが)PhantomJSを利用しJavascriptを動作させています。
API化するとブラウザ上でリクエストすればJS Renderから返却されたHTMLが描画出来、XpathがJS Render経由のHTMLでも問題なく取得出来ることを検証することが出来ます。
Conclusion
以前第12回 AWS Startup Tech MeetupのLTで少しアペルザのクローラプラットフォームについて紹介する機会がありましたが、今回はエンジニアブログということでより掘り下げてみました。
すると社内にも適切なドキュメントが無いことに気づくことが出来、現状の確認と振り返りをする良い機会となりました。大体このようなプラットフォームと呼べるようになるまでに2年かかっています。個々のサービス・ツールはそれぞれ1ヶ月位で開発しましたがクロールからアペルザの商品データのデザイン・運用・機能改善などを含めて発展させるための2年間とも言えます。弊社CTOから検索サイトを作りたいから手伝ってくれと言われアペルザに転職しRubyによるクローラー開発技法 巡回・解析機能の実装と21の運用例を買って読み始めたときを思い出すと感慨深いですがエモくなってきたので割愛します。
クロールは様々なサービスで必要な技術なので参考になれば幸いです。