Overview
https://aperza.com is a service where industrial engineers can search and order models (machines) from different manufacturers/distributors.
We recently introduced an e-commerce (https://ec.aperza.com) and are continuously improving our service.
Improvement is easily achieved because of our CD (Continuous Delivery) pipeline
This post is about what CD is and how you can implement it to get results.
What is CD (Continuous Delivery)
“Continuous Delivery is the ability to get changes of all types—including new features, configuration changes, bug fixes and experiments—into production, or into the hands of users, safely and quickly in a sustainable way.” - https://continuousdelivery.com/
Doing so will make it faster to deliver features and verification of experiments. Giving us an invaluable advantage over our competition.
What is the difference between CI, CDelivery and CDeployment
- Continuous Integration (CI) - is about integrating source code and building it by running tests (this does not include deployments)
- Continuous Delivery - User intervention to deploy with a button push
- Continuous Deployment - Deployments are automatic after pushing to repository
Tools you can use for CI/CD
- https://travis-ci.org/ (SaaS)
- https://circleci.com/ (SaaS)
- https://jenkins.io/ (locally hosted)
- https://concourse-ci.org/ (locally hosted)
- https://www.gocd.org/ (locally hosted)
Easiest ones would be to use SaaS, it saves you a lot of headache for server maintenance, backups, etc. However for us cost was a concern so we decided to go for a locally hosted servers.
We we’re currently using Jenkins but the pipeline is just not comprehensive enough. It can be achieved by using multiple plugins (More at https://www.gocd.org/2017/04/25/gocd-over-jenkins.html)
Concourse is too big for our use case and ultimately decided with GoCD (especially with the VSM - visualization feature)
GoCD Structure
The documentation in GoCD is concise so I’ll only give a brief overview here * Pipeline (contains materials and multiple stages, executes sequentially) * Material (your source code) * Stages (contains multiple jobs, executes sequentially) * Jobs (executes tasks in parallel) * Task (a task inside a job) * Agent (responsible for executing job tasks)
You can read more about concepts in https://docs.gocd.org/current/introduction/concepts_in_go.html
Requirements to Setup GoCD
- GoCD Server
- GoCD Agent(s)
- your pipeline configuration
GoCD Server stores your pipeline information, account authentication, scheduling the agents and more. Agent is responsible for building the jobs defined in your pipeline
Tracking Pipelines-as-code for configurations
All these configurations can be managed from the UI. However tracking/going back to specific pipeline is impossible;
To address this there is a concept of Pipelines as code which means defining your pipelines, stages, jobs all from source code instead of the tool
This allows us to version and track the changes made on the pipelines, making it easier to find changes made on the pipelines.
By default GoCD uses XML for pipeline definition however this is not the most human-readable format.
To address this we use a .yaml file instead and there’s a wonderful plugin available at https://github.com/tomzo/gocd-yaml-config-plugin
Setting up GoCD Server / GoCD Agents
Installation instructions are provided by GoCD and I won’t repeat it here https://www.gocd.org/download/#redhat (They have windows/osx variants too)
Note: It is better to run the agent and server separately to prevent the server from being affected (ie. expensive processes ran by an agent);
What the process look like before
 Diagram A.1
Diagram A.1
What the process look like after
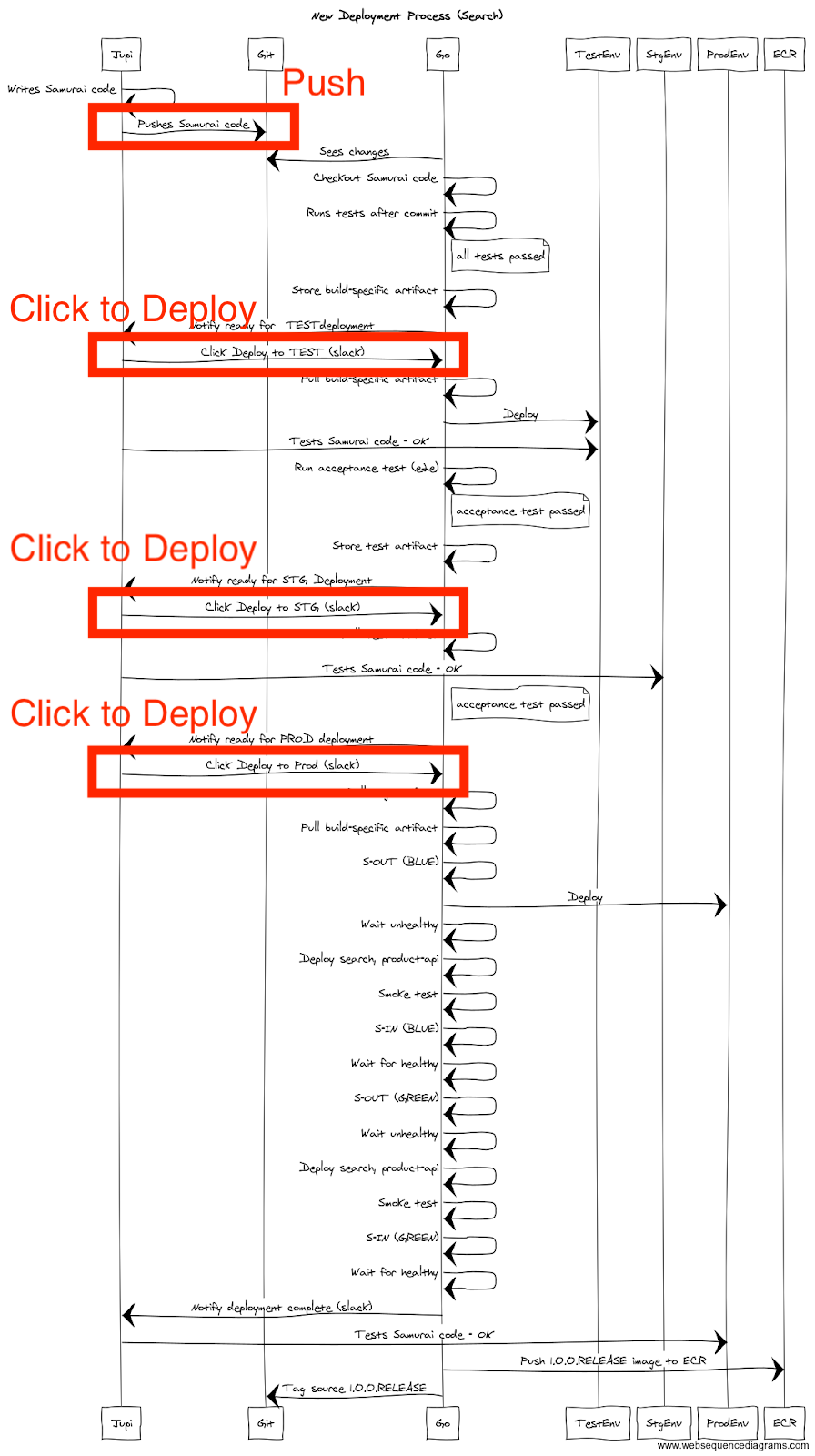 Diagram B.1
Diagram B.1
How one of our CD pipeline looks like now
- Developers would push features to Git repo
- This would then be automatically picked up by GoCD
- GoCD would build and run automated test tests (important in CD - provides confidence in code changes)
- Build file would then notify in Slack about deployment
- If build passes, notify slack about available deployment
- Dev clicks a button to deploy to TEST env
- Perform service out for target domain (AWS ALB) during deployment
- Perform deployment
- Ensure services are up via smoke-test
- Perform service in for target domain (AWS ALB) during deployment
- Save build artifact in Test
- Run automated acceptance tests (provides confidence that service is running as expected)
- If acceptance/capacity tests passes, notify Slack for available STG deployment
- Same process from #5-#12 for STG environment (use same build-artifact used in test this provides confidence that we’re using same version in Test)
- If acceptance/capacity tests passes, notify Slack for available PROD deployment
- Same process as #14 for Prod environment (use same build-artifact used in test this provides confidence that we’re using same version in TEST and STG)
- Tag all git related projects
- Push built docker image to Cloud container (AWS ECR or likes)
- Notify Slack that release is complete.
How 1 of our pipelines look like
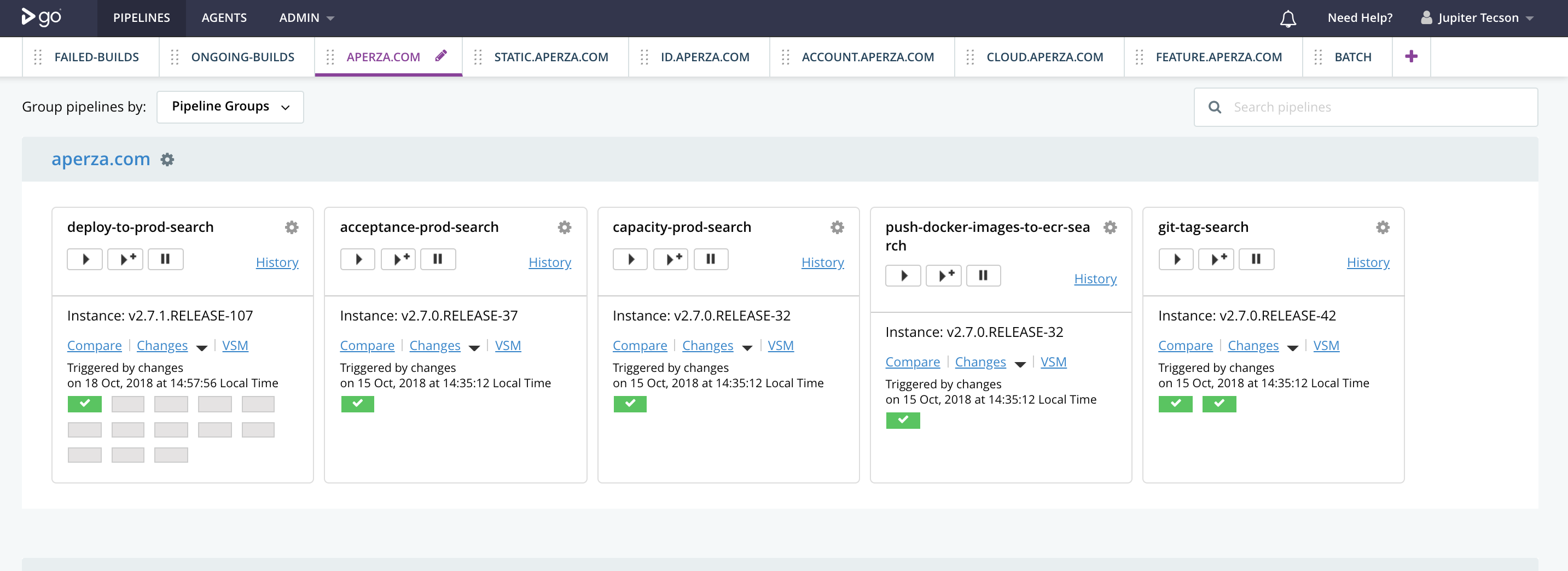 Diagram C.1
Diagram C.1
How 1 of our pipelines look like (VSM view)
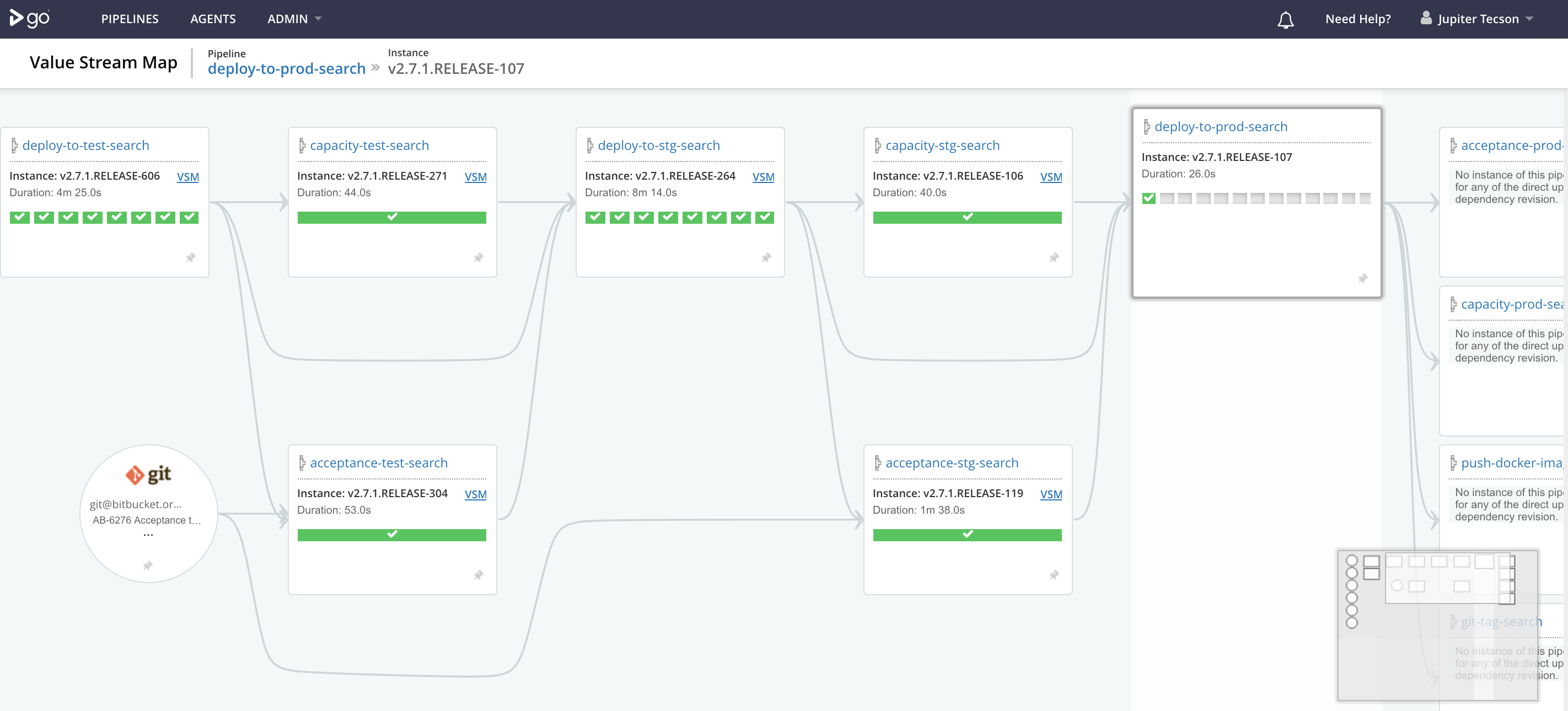 Diagram C.2
Diagram C.2
How our agent look like (VSM view)
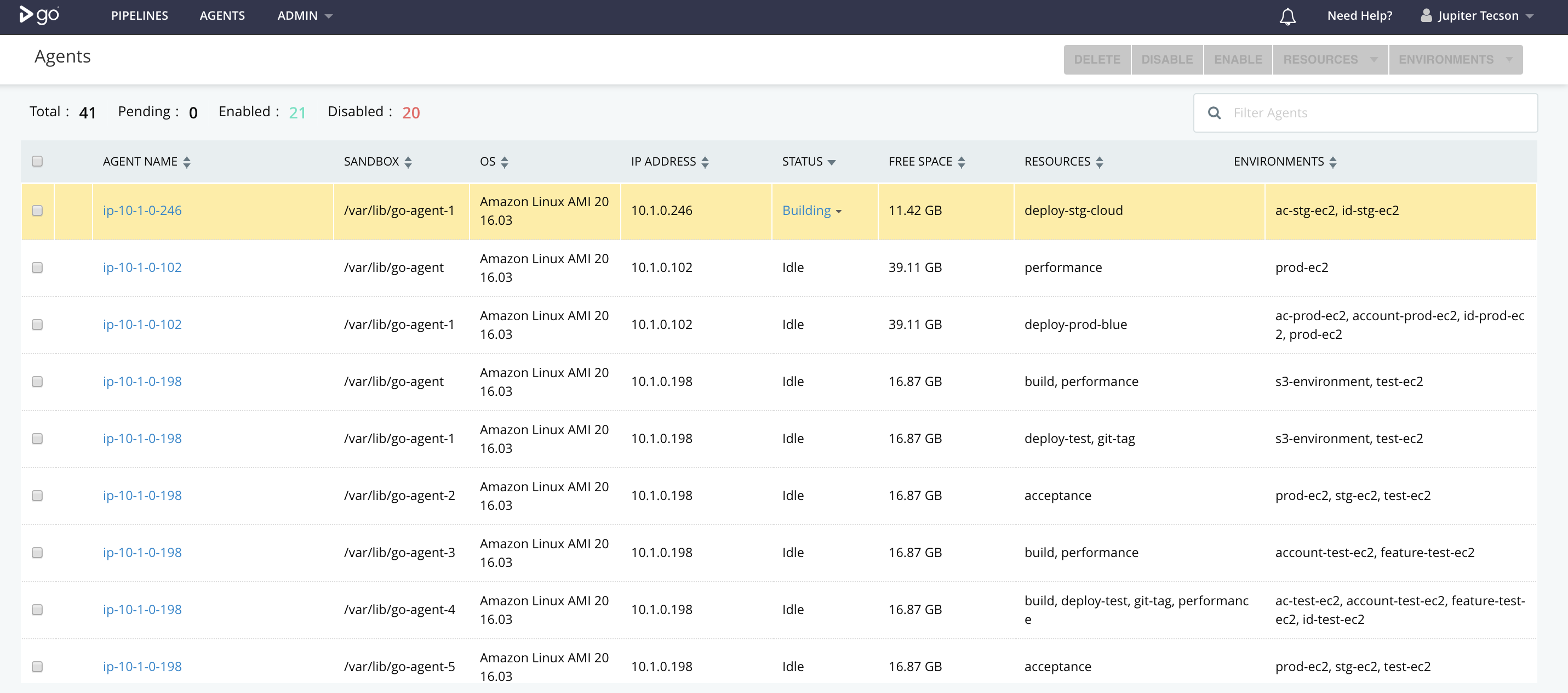 Diagram C.3
Diagram C.3
As you can see from Diagram A.1 there are a lot of steps involved that requires knowledge, about what scripts to run, which servers to login to, what branches to deploy, and apart from that the old process does not have automated tests.
This can be error-prone as humans are dealing with writing/executing scripts.
After CD was implemented * Anyone can deploy (no server/script/command knowledge required) * Great confidence about state of application with automated tests * Less error prone (only get’s better as scripts are automated) * Lesser need for documentation and do more productive work instead
Conclusion
The main challenge when setting up CD was how your pipeline should look like (stages and jobs - Diagram C.1, C.2), how many agents should you run (depends on spec, but limit the memory on builds to not hog the entire server, Diagram C.3); Other challenges would be setup for authentication (with google integration), making pipeline-as-a-code, slack integrations, writing scripts, and memory optimizations;
To recap, implementing CD would require * Automated test cases, takes a lot of time as features continue to develop * Scripts to automate everything, write once, but once setup, you’re good to go * Good pipeline definition, build once, deploy everywhere, ensures confidence in code in different environments
Overall, our releases had been more frequent, sometimes per ticket instead of the whole sprint. This iterative/frequent approach introduces less errors as the releases are gradual and it’s easier to isolate problems during releases;
Continuous Delivery has made us more confident about our applications and this gives us a great advantage in delivering features to the market faster than the competition Also developers are can focus more about features instead of server, deployments, and the likes
My primary reference was Jez Humble’s book https://www.amazon.com/Continuous-Delivery-Deployment-Automation-Addison-Wesley/dp/0321601912) that discusses the concepts above in more detail. if you want to deep-dive I recommend that book. And hopefully more teams/companies would utilize these techniques/processes.
If you would like to be part of us improving the manufacturing industry check out our Aperza Hiring Page
About Jupiter Tecson
Jupiter is a full-stack engineer in Aperza working on https://www.aperza.com/en/ He is passionate about making developer’s life more productive and easier
Introducing CD was one of his initiatives in Aperza
Occasionally he would push some research of new tech at https://github.com/jupiterhub As a hobby, he likes to explore new places and document his travels at YouTube.